AI agents are getting better at reading files, searching across folders, and answering questions over long contexts. But a crucial piece of personalization is still missing: agents rarely understand how a person actually works.
Most agent personalization today starts with explicit instructions. Users write a
CLAUDE.md, an AGENTS.md, Cursor rules, or a long preference prompt
that explains their style. This helps, but it has a structural limitation:
people are not always good at describing their own habits, and even when they are, those habits
change over time.
At Synvo AI, we believe the next generation of personal and enterprise agents needs a deeper form of context. It is not enough for an agent to know what documents exist in a workspace. It should also learn how a user reads, writes, organizes, revises, and navigates through that workspace.
That is the motivation behind FileGram, a research framework for grounding agent memory and personalization in file-system behavioral traces through controlled, persona-driven simulations and diagnostic evaluation.
Why File Behavior Matters
When a person works with files, they leave behind rich behavioral signals.

Some users read sequentially, opening documents one by one before making edits. Others search aggressively, jump between folders, and only inspect targeted sections. Some users create detailed intermediate drafts; others keep a lean workspace and delete temporary files quickly. Some reorganize projects into deep hierarchies, while others prefer flat directories and descriptive filenames.
These patterns are not superficial preferences; they shape how an AI agent should assist. A meticulous planner may need preserved provenance, intermediate reasoning, and careful detail, while a fast scanner may need concise summaries, direct links, and minimal interruption. A personalized agent should adapt to these differences without requiring the user to manually describe every preference.
File systems are where much of this behavior becomes observable. Reads, writes, edits, moves, renames, deletions, generated artifacts, screenshots, PDFs, and multimodal documents together form a trace of how people transform information into work.
Files tell an agent what a user knows.
Behavioral traces tell an agent how a user works.
The FileGram Framework: Engine, Benchmark, and Memory
FileGram has three components, each designed to make file-system behavioral memory measurable, reproducible, and useful for agent personalization.
01 · Data engine
FileGramEngine
Generates persona- and task-conditioned file-system workflows with typed actions, content deltas, and multimodal artifacts.
02 · Evaluation
FileGramBench
Turns behavioral traces into diagnostic QA across nine sub-tasks for profiling, reasoning, drift detection, and grounding.
03 · Memory
FileGramOS
Builds user profiles from atomic file-level signals through procedural, semantic, and episodic channels.
FileGramEngine: Generating Realistic Behavioral Traces
FileGramEngine is a persona-driven data engine that synthesizes controlled file-system workflows conditioned on specific user profiles and tasks. Instead of collecting only final answers or static documents, it records fine-grained behavioral trajectories: typed file actions, content deltas, generated artifacts, and how the workspace evolves over time.

From just 20 behavioral profiles and 32 workspace tasks — spanning understanding, creation, organization, synthesis, iteration, and maintenance, across both text-centric and multimodal scenarios — the engine produces a large, controlled corpus:
behavioral trajectories
atomic actions
agent-generated files
multimodal files
This gives researchers a controlled environment for studying how file-level behavior reveals user preferences.
FileGramBench: Evaluating Behavioral Memory
FileGramBench turns behavioral traces into diagnostic questions. The benchmark asks whether a memory system can infer stable user patterns, disentangle mixed traces, detect persona drift, ground answers in files, and reason over multimodal artifacts.
The benchmark includes 4,653 QA pairs across nine sub-tasks organized into four tracks:
- Understanding — attribute recognition, behavioral fingerprinting, and profile reconstruction
- Reasoning — behavioral inference and trace disentanglement
- Detection — anomaly detection and persona shift analysis
- Multimodal grounding — file grounding and visual grounding
This setup tests a different kind of memory from standard retrieval benchmarks. The goal is not simply to find a relevant paragraph. The goal is to reconstruct how a user behaves across time.


Profiles
behavioral user styles
Tasks
workspace scenarios
Trajectories
file-system workflows
Benchmark
behavioral QA pairs
FileGramBench combines dataset scale and task diversity: 20 behavioral profiles, 32 workspace scenarios, 640 file-system trajectories, and 4,653 QA pairs across nine sub-tasks for understanding, reasoning, detection, and multimodal grounding.
FileGramOS: Bottom-Up Memory for Personalization
FileGramOS is a bottom-up, action-aware memory framework designed around behavioral traces. Rather than summarizing an entire session into a generic note, it builds profiles from atomic file-level signals through three complementary channels:
- Procedural memory — how the user works. We turn atomic actions into a compact behavioral fingerprint and aggregate it across trajectories into stable habits.
- Semantic memory — what the user produces. A vision-language model reads file snapshots and edits into a cross-session view of the user's style and structure.
- Episodic memory — how behaviors persist or shift. We segment trajectories into episodes and flag outliers, separating a deliberate variation from a real behavioral shift.
This bottom-up structure is important. Premature summarization can erase the small signals that matter for personalization. FileGramOS keeps the behavioral evidence grounded, then consolidates it into higher-level user models.

Results: How Memory Systems Perform on FileGramBench
We evaluate FileGramOS against eleven baseline memory systems on FileGramBench under a shared two-stage protocol — every system ingests the same raw trajectories and answers with the same backbone (Gemini 2.5-Flash), so the only variable is how each one structures memory. Scores are accuracy (%) averaged across the nine sub-tasks.
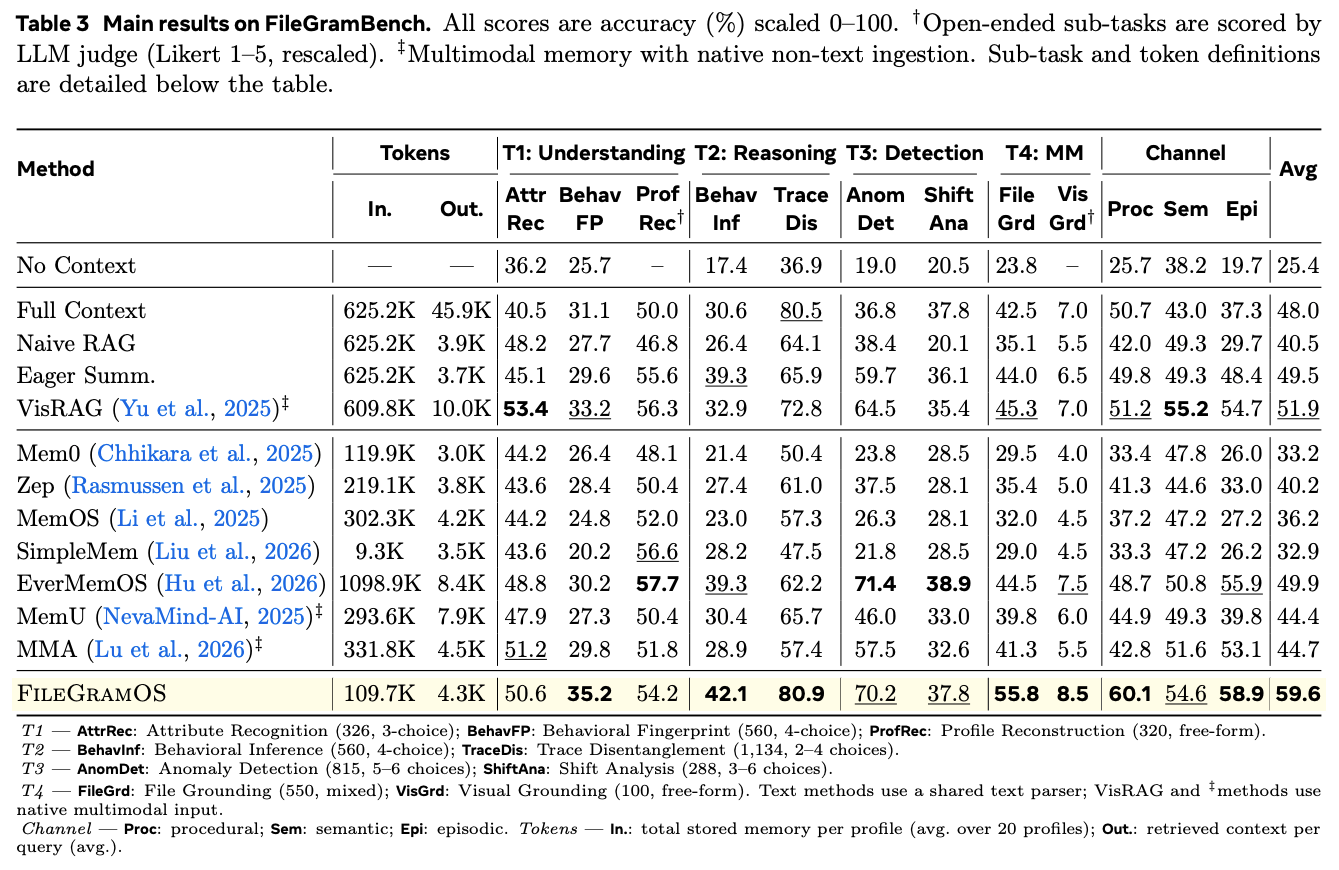
FileGramBench leaderboard
FileGramOS leads FileGramBench against 11 baselines.
Timing Is Everything: Why Structure Beats Summaries
FileGramOS reaches 59.6%, ahead of the strongest narrative baseline EverMemOS (49.9%). The gap comes down to when abstraction happens. Narrative-first systems summarize each trajectory into prose at ingest time, discarding the signals that separate one worker from another — read counts, folder depth, edit size — so two very different users end up with the same adjectives ("structured", "methodical", "comprehensive"). FileGramOS keeps those raw signals and only interprets them at query time.
Inside the Memory: What FileGramOS Stores
Accuracy improves because FileGramOS does not only store text snippets. It keeps the behavioral evidence organized by how the user works, what they produce, and when those patterns repeat. Hover or focus on the leaderboard above to inspect representative memory views based on each adapter's retained evidence and structure.
FileGramOS
Grounded behavioral profile
Semantic: structured technical writing with detailed revision.
Episodic: repeated small edits and pragmatic cleanup across sessions.
Noticing Is Easier Than Explaining
The benchmark exposes a ceiling between noticing and explaining: systems that aggregate behavior across sessions detect anomalies well (past 70%, versus 21–26% for flat memories like Mem0 and SimpleMem), but every method falls below 39% when asked which habit shifted and in which direction. Sensing a shift is far easier than naming it.
When Raw Context Wins — and When It Doesn't
Raw evidence is sometimes its own kind of memory: Full Context (48.0%) ties FileGramOS on trace disentanglement (80.5% vs 80.9%) yet collapses on cross-session anomaly detection (36.8% vs 70.2%). Multimodal methods tell a parallel story — MMA (44.7%) and MemU (44.4%) never beat the best text-only systems, since a rendered page image cannot see directory depth or naming conventions.
Frugal Memory, and an Honest Gap
FileGramOS is also efficient — about 110K tokens of memory per user and 4.3K per question, versus 625K and 45.9K for full-context prompting. The honest caveat: on real human screen recordings every method drops to single digits, making the sim-to-real gap — with shift attribution and profile reconstruction — the frontier behavioral memory has to cross next.
From File Understanding to Behavioral Context
Synvo AI has been building contextual intelligence systems that help agents understand complex, multimodal file systems. FileGram extends this direction from document understanding to behavioral understanding.
For Synvo, FileGram is not a separate research detour. It is a way to make the Contextualization Engine and local agent experience more personal: if the existing memory layer helps agents understand what is inside a workspace, FileGram studies how that workspace changes as people read, write, revise, organize, and collaborate.
Traditional file intelligence asks: What information is inside these files? FileGram asks an additional question: What do these file interactions reveal about how this person works? That shift matters for both personal and enterprise agents.
In an enterprise setting, two analysts may work with the same set of reports but have very different workflows. One might carefully compare every source before drafting. Another might quickly produce a first version, then revise through many small iterations. A useful agent should not treat these users identically.
In a developer setting, two engineers may work in the same repository but expect different collaboration styles from an AI coding assistant. One may prefer explicit plans and conservative edits; another may prefer fast implementation and compact explanations. These expectations are often visible in the filesystem long before they are written in a configuration file.
Why This Matters
These benchmark gaps matter because they point directly to the product problem: better memory should change what an agent can actually do for you.
- Agents that adapt their communication style to a user's workflow
- Local assistants that preserve personal working habits across tools
- Enterprise agents that understand not only shared knowledge, but team-specific operating patterns
- Evaluation pipelines that measure whether memory systems capture behavior, not just content
This matters most as AI agents move from isolated chat interfaces into real work environments, where they increasingly act on behalf of users and need a grounded model of intent, preference, and workflow.
Looking Ahead: Toward Behavioral Memory at Scale
FileGram is a first step toward behavioral memory for AI agents, not a claim that real-world behavior understanding is solved. The benchmark intentionally exposes hard open problems such as shift attribution, multimodal grounding, and the gap between controlled traces and noisy real-world workflows.
There are several directions we are actively exploring:
- Scaling from controlled simulated trajectories and screen-recording pilots to broader opt-in user studies
- Integrating behavioral profiles with local agent products
- Improving privacy-preserving profiling pipelines
- Extending FileGramOS to richer multimodal and temporal signals
- Studying how behavioral memory improves long-running agent collaboration
We are releasing FileGram to invite researchers, builders, and product teams to study this problem with us.
If document intelligence was the first layer of contextual AI, behavioral intelligence is the next one. The agents that become truly useful will not only retrieve what we wrote. They will learn how we work.
Citation
Please cite this work as:
@article{liu2026filegram,
title={FileGram: Grounding Agent Personalization in File-System Behavioral Traces},
author={Liu, Shuai and Tian, Shulin and Hu, Kairui and Dong, Yuhao and Yang, Zhe and Li, Bo and Yang, Jingkang and Loy, Chen Change and Liu, Ziwei},
journal={arXiv preprint arXiv:2604.04901},
year={2026}
}